


Join me in NYC at Habibi Tech Summit on Saturday, August 30th inshAllah. I'll be speaking in the afternoon about AI and ethical tech, and how Muslims can help control the entire "AI stack". Habibi Tech Summit 2025 brings together Muslim financiers, policymakers, physicians, legal experts, and tech executives to ensure our communities are not left behind. This high-impact summit is designed to empower Muslim leadership in AI and spark collaboration across industries.
Salaam!
After much delay and anticipation, OpenAI revealed its newest model, ChatGPT-5, to the public. So what's the verdict? Are we closer to "artificial general intelligence" or "superintelligence"? Is AI a threat to humanity and our jobs? With some AI researchers reportedly making over $100 million, should we all start learning AI?
Before I share my perspective, let me provide some context about my background. I have been working in AI since 2004, back when the field was called "pattern recognition." I completed my Ph.D. in AI in 2013, and my dissertation won the "Best Dissertation Award" for work on AI and climate change. In 2015, I founded a $30 million startup at the intersection of AI and healthcare with funding from the Bill and Melinda Gates Foundation. I have also built AI systems for three separate billion-dollar companies. Since 2014, I have been a professor and/or taught AI at Columbia, MIT, Stanford, and USC educating tens of thousands of students globally.
The point of this background is that today's newsletter isn't a reactionary hot take, but rather an in-depth analysis from a Muslim AI practitioner with twenty years of experience in the field.
My goal is to provide a nuanced perspective on AI and ChatGPT, as well as guidance on how we, as Muslims, can thoughtfully approach this technology.
Here's the spiritually intelligent reframe:
AI is simply a technology, much like a spoon or a vaccine: a human-made invention designed to solve problems. While all human-made technologies carry unintended negative consequences, AI's benefits have been grossly exaggerated while its harms have been significantly downplayed.

Part I - AI: A Nuanced History
Artificial intelligence (AI) is a subfield of computer science focused on designing "intelligent" systems. While there remains significant debate about what "intelligence" actually means, it is generally understood as the ability to "improve at a task as more data are observed." The field of AI began in the 1950s, and for the first twenty years, researchers were still exploring whether machines could truly "learn." Interestingly, artificial general intelligence (AGI) was never the primary goal of academic AI from the 1950s until around 2022. In fact, that term was seldom discussed in AI circles, neither in terms of promises nor dangers.
From the 1970s until the early 2000s, AI remained largely dormant due to funding cuts and fundamentally flawed approaches, with little interest beyond hardcore academics. However, the majority of the scientific principles that would later influence ChatGPT and virtually every modern AI breakthrough were developed during this era, building on foundations from statistics and signal processing.
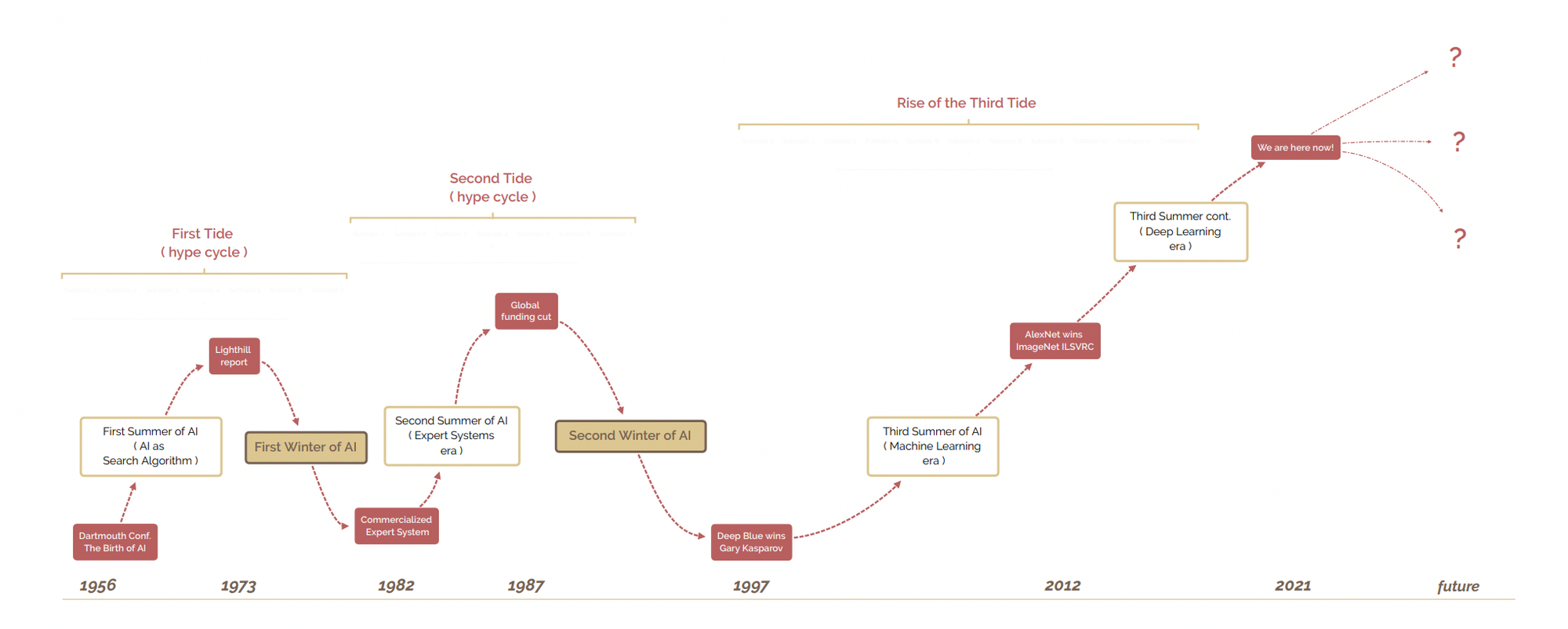
The landscape began changing rapidly in the early 2000s. Three conditions converged to create the perfect storm for the AI boom of the 2010s: the Internet, Moore's Law, and the rise of Big Tech.
The first catalyst was the Internet and the massive amounts of data it generated: text, images, audio, and video. Since AI focuses on building systems that improve with more data, the Internet became a tremendous boon for the field.
The second factor was Moore's Law, named after Intel co-founder Gordon Moore, which observed that computer processors doubled in performance every 24 months while costs halved during the same period. This principle held true during the early 2000s, when storage and computing costs decreased dramatically, making AI algorithms 10-100 times faster and cheaper than just a decade earlier.
Finally, this decade witnessed the emergence of the first major internet startup successes that became known as Big Tech: Google, Amazon, Facebook, Netflix, and others. The role that Big Tech would play in shaping AI development would become increasingly significant, as these companies used their popularity, positive public perception, and substantial funding to influence the types of AI projects that academics would pursue.
The Perfect Storm in Action: Image Classification
To illustrate how these three conditions - the Internet, Moore's Law, and Big Tech - created major breakthroughs in AI, let's examine the task of image classification. Image classification is an AI application where you provide an image to a model, and the system identifies what's in the image, such as a cat, dog, or car. While this task is trivial to a human, it was a major challenge in AI that required decades of research and investments.
One of the earliest AI models used for image classification employed what's known as a neural network. One of the first successful neural networks in image classification was designed by a team at AT&T Bell Labs in 1989. The model, named LeNet after one of its designers (Yann LeCun, who is now Meta's Chief AI Scientist), successfully classified images of handwritten digits. Their refined model, LeNet-5, was published in 1998 and represented a significant achievement for its time. However, these neural networks required enormous amounts of data and computing power that simply didn't exist in the late 1990s.
A live demo of LeNet identifying hand written digits
Fast forward to 2012, when the convergence of our three factors produced a breakthrough. A model developed by researchers at the University of Toronto (and Google), called AlexNet (named after its creator Alex Krizhevsky and considered a breakthrough model in AI), used essentially the same foundational approach as LeNet with some notable refinements. The critical difference wasn't in the underlying science, but in the resources available. While LeNet-5 was trained on 60,000 small, grayscale images of handwritten digits, AlexNet had access to 1.2 million high-resolution color images from the ImageNet dataset - a product of the Internet era's data abundance. In total, AlexNet had access to approximately 4,000 times more data than LeNet and roughly 1,000 times more computational power, thanks to advances in graphics processing units (GPUs) and the declining costs predicted by Moore's Law.
This was the start of the era of "scale is all you need" where most of the gains we are seeing in AI aren't due to major scientific breakthrough but to bigger models thanks to more data and computational power.
Big Tech's Invisible Hand in AI
If you were to ask anyone about the top AI applications today, they would very likely list:
- Search and discovery
- Recommender systems
- Image and text classification
- Personalization (including targeted advertising)
- Chatbots
- Recent generative AI developments like image and video generation
Upon closer examination, AI products numbered 1 through 5 were built by Big Tech primarily to serve Big Tech's needs.
These companies found themselves overwhelmed by their own success: millions of images uploaded to Facebook every minute, millions of hours of video uploaded daily to YouTube, thousands of movies and songs requiring management for streaming platforms. These companies grew so rapidly in popularity that they needed advanced tools to manage this data deluge.
This means that the majority of AI technologies were not designed to serve ordinary people like you and me, but rather to help Big Tech companies generate more revenue. How often do you personally need a recommender system in your daily life (beyond Netflix or Spotify)? How often do you need to process millions of images to identify violence or inappropriate content (like Instagram or TikTok)? How often must you sift through millions of messages to identify hate speech (like Twitter or Reddit)? For most people, the answer is never. However, Big Tech has become exceptionally skilled at crafting narratives that present these tools as having significant benefits for users, while convincing us of their importance and utility, when in reality they provide marginal benefit to most individuals.
How did we arrive at this point? How did we transition from the hope of creating AI that could potentially save lives, improve education, or help preserve our planet, to merely developing AI systems designed to sell more advertisements and encourage increased consumption?
The way Big Tech influenced the types of research questions and applications that the AI academic community investigates was gradual and subtle, but has resulted in academia almost exclusively working on problems that benefit Big Tech rather than society as a whole.
This influence began early with small grants to academics (typically $10,000-$30,000), named professorships (where Google would provide gifts to universities in exchange for naming rights), graduate research and postdoctoral fellowships, high-paying summer internship programs for Ph.D. students (approximately $30,000-$50,000 per summer), and residency programs allowing academics to spend one- to two-year sabbaticals within Big Tech companies.
To illustrate Big Tech's growing influence on AI research, consider one of the top AI conferences, NeurIPS (formerly known as NIPS), where many state-of-the-art AI research papers are published. In 2006, there was only one organizer from Big Tech (Microsoft Research), while the rest came from academic universities. By 2024, there were at least 17 organizers from Big Tech companies and 24 from the broader tech industry. Why does this matter? These organizers, and more importantly the reviewers, are the gatekeepers who decide which research gets published. As employees of Big Tech companies, they naturally gravitate toward a narrow set of technologies useful to their employers, creating bias in acceptance decisions toward those topics. Over this nearly twenty-year period, we have witnessed the breadth of topics published in academic AI gradually narrow to focus primarily on subjects of interest to Big Tech, because these companies effectively control the acceptance process. This dynamic pushes graduate students and professors to research and write about these specific topics to ensure acceptance in prestigious publications, which determines career success in terms of graduation for students and tenure and promotion for faculty members.
Up until the 2010s, there was nothing fundamentally problematic with AI as a field. It represented a legitimate area of computer science that aspired to discover interesting and previously unknown patterns in large datasets, with the hope of solving major societal problems alongside some commercial applications, such as automation and improved customer targeting. Similarly, while we began seeing some negative effects from Big Tech companies by the late 2010s, their practices weren't dramatically different from other profit-driven industries that have historically prioritized financial returns over public welfare, such as Big Tobacco, Big Pharma, or Big Food.
Part II - ChatGPT and Large Language Models
Most people don't realize that the "GPT" in ChatGPT is an acronym standing for "Generative Pre-trained Transformer." A Generative Pre-trained Transformer is essentially a sophisticated neural network designed specifically for processing and generating text. The first GPT model, known as GPT-1, was released by OpenAI in 2018. The model is called "generative" because it predicts the next word (or series of words) in a sentence through a process known as "next token prediction." GPTs are "pre-trained" on vast, generic datasets to learn broad language concepts and patterns, then fine-tuned for specific applications such as conversational chat. Finally, "transformer" refers to a particular type of neural network architecture that has proven especially effective for language tasks.
While GPT-1 built upon several previous innovations, the real turning point for what we now call "large language models" came in 2013 with breakthroughs in neural networks for text processing, particularly Google's word2vec model. Crucially, when these large language models first emerged, there was no discussion of artificial general intelligence or claims that they would serve as magical solutions to humanity's problems, as they are often marketed today. They were simply specialized neural networks trained on massive collections of text (taking advantage of the Internet's abundant textual data) with practical goals like text summarization and translation (again, that mostly of interest to Big Tech)
"But James, if ChatGPT is just a neural network designed for text, why does it seem so much more magical than the limited neural networks you described earlier for image classification?" There are two key factors that make ChatGPT appear far more powerful than traditional neural networks used for tasks like image classification.
The first factor is the sheer scale of data that ChatGPT was trained on, which encompasses essentially the entirety of the publicly accessible internet, including substantial amounts of pirated and copyrighted material. However, large training datasets alone don't explain ChatGPT's popularity, since we've had models trained on vast amounts of data before without achieving similar widespread adoption.
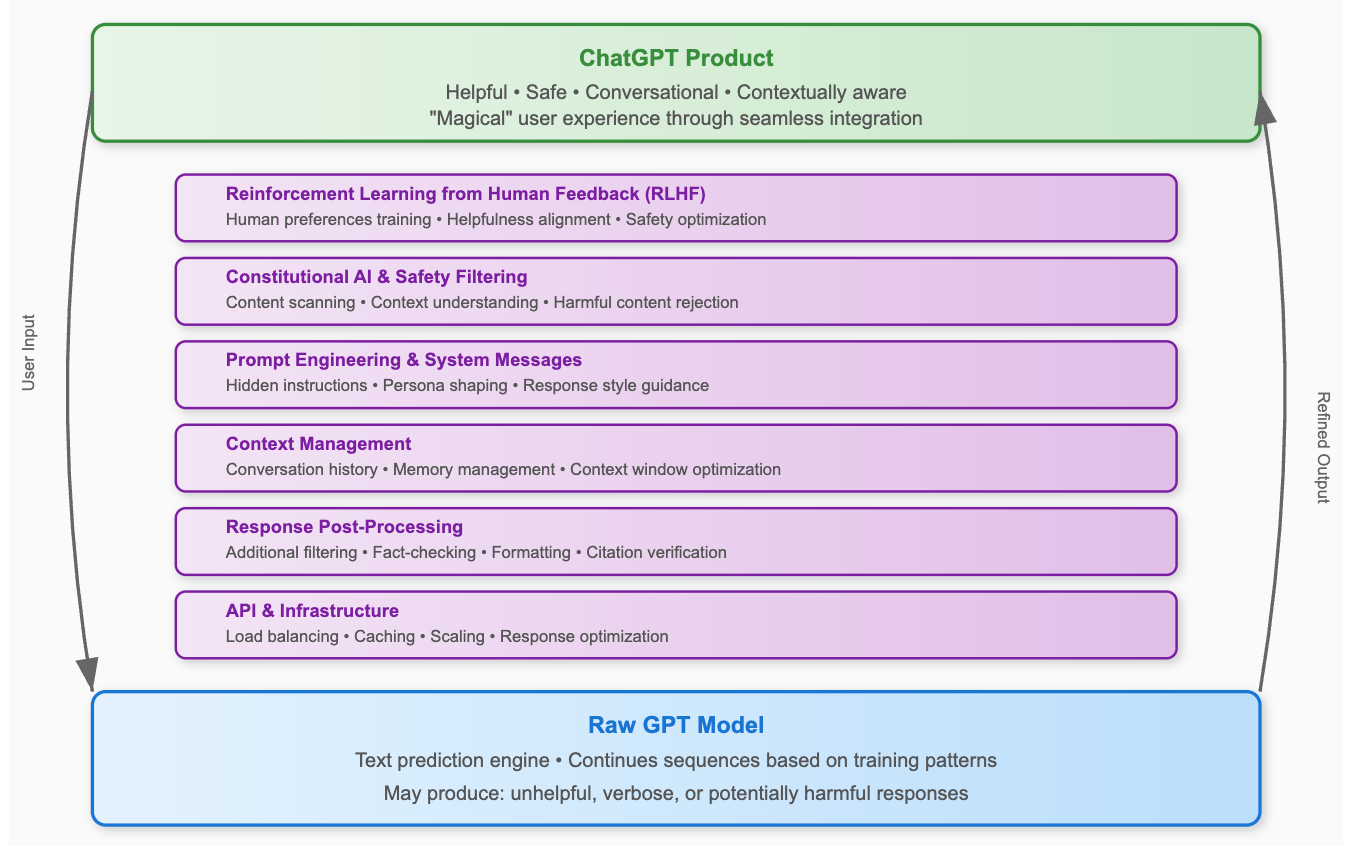
The crucial second factor is that ChatGPT is not merely an AI model, it's a professionally crafted software product. The underlying GPT model is essentially a sophisticated text prediction engine trained to continue sequences of text. When you provide input text, it predicts what should logically come next based on patterns it learned from its massive training dataset. While this raw capability is remarkably powerful, it doesn't naturally produce the helpful, safe, and conversational responses that users would expect.
To create the seemingly magical user experience, OpenAI employs several sophisticated techniques to refine the raw model output into responses that meet user expectations. These techniques include:
Reinforcement Learning from Human Feedback (RLHF): This represents perhaps the most crucial post-training step. Human trainers evaluate and rate the model's outputs across thousands of examples, teaching the system to produce responses that align with human preferences for helpfulness, accuracy, and safety. This process transforms the raw text prediction engine into something that appears useful and conversational.
Prompt Engineering and System Messages: Behind the scenes, your actual question gets wrapped in carefully crafted instructions that remain invisible to you as the user. These "system prompts" tell the model how to behave, what persona to adopt, what tone to use, and what types of responses to prioritize in different contexts.
Response Post-Processing: The model's outputs typically undergo additional layers of filtering, fact-checking, and formatting before reaching users. This might include citation verification, safety checks to remove harmful content, or structural improvements to enhance readability.
Beyond these publicly known techniques, there are likely dozens of additional engineering steps that occur behind the scenes. These sophisticated post-processing systems contribute significantly to the massive costs associated with training each ChatGPT model (the latest iteration is estimated to have cost over $1 billion to develop and deploy).
This engineering complexity explains why building competitive conversational AI isn't simply a matter of having access to a powerful language model. It requires substantial engineering expertise and resources to create all the surrounding systems that make the interaction feel natural, reliable, and genuinely helpful to users.
Demystifying LLMs
So how do LLMs like ChatGPT work? As I mentioned before, there are what we call next token predictors. Given a body of text, it simply predicts the next word, the most likely next word in the sequence. Here is a brief demo:
A intro to how LLMs work in 5 minutes!
As I explained in the video, all LLMs do, is look at massive amounts of documents and then apply pattern matching across billions and billions of documents. An LLM is simply answering this question: given a sentence, and based on the historical data that I've seen, what is the most likely next word in this sentence?
The illusion of intelligence
So if all that LLMs do is predict the most likely next word in a sentence, how come they sound so intelligent? There are several tricks that LLMs use that give the "illusion of intelligence" but rest assured these models are neither "intelligent" nor "think" or "reason". Don't get me wrong, LLMs can do some pretty amazing things but it's not "thinking".
As I mentioned with ChatGPT's development, creating the appearance of intelligence requires multiple layers of post-processing: Reinforcement Learning from Human Feedback, sophisticated prompt engineering, response filtering, and countless other techniques that transform raw pattern-matching into something that feels conversational and helpful.
This engineering infrastructure is what makes the illusion so compelling. OpenAI and other companies didn't just build a better pattern matcher, they built an entire system designed to make pattern matching feel like genuine intelligence. The billion-dollar development costs aren't going toward creating actual reasoning; they're going toward making statistical text generation feel more human-like.
The Stochastic Parrot Problem
In 2021, Timnit Gebru, Emily Bender, and colleagues introduced the concept of "stochastic parrots" systems that brilliantly remix human-generated knowledge without any underlying model of truth, causality, or understanding. These models excel at generating text that looks like reasoning because they've absorbed near infinite examples of human reasoning, not because they grasp the underlying logical principles. When you ask ChatGPT "what is 1+1"? It answers 2 not because it understand the concept of mathematics or addition but because 2 is the overwhelmingly probable next token of "1+1="
The Mirage of Chain-of-Thought Reasoning
The most compelling evidence for AI "intelligence" comes from Chain-of-Thought (CoT) prompting, where models like GPT-5 produce step-by-step reasoning that mirrors human thought processes. When you ask a model to "think step by step," it generates intermediate reasoning steps that look remarkably human-like. This capability has led many to believe that LLMs engage in genuine reasoning.
My former colleague Huan Liu at Arizona State University conducted systematic experiments training LLMs from scratch in controlled environments. Their findings were unambiguous: CoT reasoning is "a brittle mirage that vanishes when it is pushed beyond training distributions."
The systems had learned to simulate the appearance of reasoning by memorizing countless examples of human reasoning from their training data, but they possessed no underlying understanding of logical principles.
When tested on tasks that required genuine reasoning (e.g. problems slightly outside their training data) the illusion collapsed entirely. Performance dropped to zero when models encountered even modest complexity beyond what they had memorized. As one researcher put it, LLMs are "sophisticated simulators of reasoning-like text" rather than actual reasoners.
The Fragility of Artificial Reasoning
What makes this illusion particularly dangerous is its fragility. The above study shows that minor perturbations such as seemingly irrelevant changes to prompt wording, format, or context can cause dramatic performance drops in even the most advanced models. Models that appear to reason brilliantly about a problem often fail completely when that same problem is presented with slightly different formatting or when irrelevant information is added.
This brittleness is incompatible with genuine intelligence. A truly intelligent system would be robust to surface-level changes in presentation. The fact that cutting-edge AI can be derailed by trivial modifications reveals the shallow nature of its apparent understanding.
There you have it. Large language models (such as ChatGPT, Claude, Gemini, etc.) are sophisticatedly engineered stochastic parrots that give the illusion of intelligence when all they have done is memorized the entirety of the internet.
Part III - The Big AI Era
By the late 2010s, the harmful impacts of AI on society and individuals were becoming clear, many of them captured in the 2016 book "Weapons of Math Destruction." Calls for transparency and accountability grew louder, but a new villain entered the chat: venture capital.
Big Tech had already morphed into a set of multi-trillion-dollar, often monopolistic, profit machines (which shedding feel-good slogans like “Don’t Be Evil” along the way). Now, a new wave of VC-backed players, such as OpenAI, had arrived. This ushered in the era of Big AI, where a handful of companies compete for total dominance of the AI landscape and its profits - willing to do whatever it takes, even at the planet’s expense, to secure control.
The Big AI Hype
So why not be honest and mention that LLMs are just an AI model like countless others, and even though they are not likely to help us reach AGI (who made AGI the end goal anyway?), they are certainly respectable and useful tools. Why hype this technology endlessly and then end up being embarrassed time and time again when it can't even count the number of "r" in "strawberries".
The illusion of intelligence has become more economically valuable than intelligence itself. Companies have discovered that systems capable of generating convincing reasoning-like text can command enormous valuations, regardless of whether they possess actual understanding.
The market isn't pricing these companies based on their ability to solve genuine problems, it's pricing them based on their ability to create compelling demonstrations of apparent intelligence.
We’re living through a speculative bubble where the promise of artificial intelligence has drifted far from the reality of what these systems can actually do. The real money isn’t in creating truly intelligent machines. It’s in selling the idea of intelligence to investors, customers, and a public eager to believe we’re on the brink of an AI revolution. This hype is why OpenAI commands a $400 billion valuation, why Safe Superintelligence (founded by a former OpenAI CTO) is worth $30 billion, and why Thinking Machines (founded by another former OpenAI CTO) is valued at $12 billion. Neither SSI nor Thinking Machines has customers, a product, or revenue.
The Ecosystem of Exaggeration
This astronomical disconnect between valuation and reality didn't emerge in a vacuum. It's sustained by an entire industrial complex of hype that profits from maintaining the illusion, even in the face of mounting evidence that these systems are not going to be more than text generators.
The Venture Capital Engine: At the foundation of this bubble sit venture capitalists who have billions invested in AI companies. Having committed enormous sums based on promises of AGI breakthroughs, VCs now have powerful incentives to amplify every incremental improvement as revolutionary progress.
Founder Theater: The entrepreneurs behind these companies face intense pressure. After raising hundreds of millions (or even billions) on the promise of AGI, founders like Sam Altman must sustain the illusion of unstoppable progress toward superintelligence. That’s why we hear grand claims about ChatGPT-5 being like “talking to a legitimate PhD-level expert in anything,” even when evidence suggests otherwise. These founders aren’t necessarily delusional - they’re simply loyal to the people footing the bill. Training ChatGPT-5 cost over a billion dollars, and your $20-a-month subscription isn’t covering that tab. It’s SoftBank and Sequoia Capital who are picking up the check and calling the shots.
The Media Amplification Machine: Tech and traditional media outlets are the next accomplices in the hype cycle, with tech journalists and commentators treating every AI development as a watershed moment. Publications like The New York Times regularly feature breathless coverage that oscillates between AI salvation and AI apocalypse narratives. Figures like Ezra Klein, despite lacking technical AI expertise, command massive audiences while amplifying the most dramatic interpretations of AI progress. These mainstream media voices lend credibility to extreme claims simply by virtue of their platforms, transforming Silicon Valley PR into seemingly authoritative journalism.
The Content Creator Economy: Beyond traditional media, an entire ecosystem of podcasters, YouTubers, "thought leaders", and AI influencers has emerged to feed public fascination with AI doom and boom scenarios. These content creators have discovered that AI hysteria (whether utopian or dystopian) generates clicks, views, and revenue. Take Mo Gawdat, the former Google executive who has built a a new career around AI apocalypse predictions, despite never having worked a in actual AI development. His background is in business operations, yet he's become a prominent voice spreading existential AI fear, because doom sells better than nuanced technical reality.
This content ecosystem thrives on extremes: either AI will solve all human problems or destroy humanity entirely. Moderate positions, that LLMs are sophisticated but limited tools, don't generate the engagement metrics that fuel the modern attention economy.

The AI Gold Rush Myth
This coordinated hype has created what can only be described as a modern gold rush, and like the California Gold Rush of 1849, the real money wasn't made by those digging for gold. History teaches us that while thousands of prospectors went broke chasing dreams of striking it rich, the merchants selling shovels, pans, and provisions became wealthy. The AI boom follows this same pattern with remarkable precision. The companies promising revolutionary AI breakthroughs are often elaborate research projects funded by speculative capital, not sustainable businesses generating real economic value.
Meanwhile, the modern equivalent of shovel-sellers, the infrastructure companies, are printing money. Here's the likely hierarchy of who actually profits from the AI gold rush:
1. AI Infrastructure Companies (The Shovel Sellers): NVIDIA, Amazon Web Services, Google Cloud, and Microsoft Azure are the undisputed winners. Every AI company needs massive computational power, specialized chips, and cloud infrastructure. Whether GPT-5 succeeds or fails, whether startups boom or bust, these companies get paid regardless. NVIDIA's market cap has exploded not because their chips are "smart", but because every AI prospector needs their shovels.
2. Government and Regulatory Capture: Governments and well-connected officials position themselves as gatekeepers, creating regulatory frameworks that benefit their preferred partners while blocking competition. The revolving door between Big Tech and regulatory agencies ensures favorable policies for established players while erecting barriers for newcomers.
3. Investors at Every Level: VCs, institutional investors, and private equity firms who got in early harvest returns by selling the dream to later investors. They profit not from AI's actual utility but from the musical chairs of ever-increasing valuations, as long as they're not holding the bag when the music stops.
4. AI Tool Companies: OpenAI, Anthropic, and similar firms occupy a precarious middle position. They command enormous valuations but burn cash at unsustainable rates. Their profitability depends entirely on maintaining the illusion of inevitable progress toward AGI while the infrastructure costs eat away at margins.
5. Application Builders: Companies building "AI-powered" applications and ChatGPT wrappers capture some value by riding the hype wave, but face intense competition and commodity pricing pressure. Most will fail as the market matures and the underlying AI capabilities plateau.
6. Media and Influencers: Journalists, podcasters, and thought leaders monetize the attention generated by AI hysteria through speaking fees, book deals, and platform growth. They profit from the narrative regardless of whether the technology delivers.
7. End Users: At the bottom of this pyramid sit the millions of workers and consumers promised that AI will revolutionize their productivity and lives. They're the ones paying subscription fees for marginal improvements while facing potential job displacement - the modern equivalent of prospectors who mortgaged everything for a chance to strike gold that mostly didn't exist.
The closer you are to the underlying infrastructure and financial mechanisms, the more likely you are to profit. The further you are from the hype and closer to the actual promised "productivity", the more likely you are to lose.
Where do we fit?
As Muslims, we have a particular obligation to see through this carefully constructed illusion and position ourselves strategically. The Quran teaches us to:
"O you who believe! If a wicked person comes to you with any news, verify it, lest you harm people in ignorance, and afterwards become regretful for what you have done." [49:6]
It is important to take all AI news with a grain of salt and not blindly share AI stories without vetting them first, lest we perpetuate this hype cycle. You can balance your AI coverage with reputable alternative voices such as Timnit Gebru, Joy Buolamwini, Tim El-Sheikh, or Jeffrey Funk.
While it is encouraging to see many AI applications serving the Muslim community, we must move beyond the application layer—beyond being mere consumers of ChatGPT subscriptions and AI-powered productivity tools. What happens when OpenAI achieves market dominance and decides to charge $10,000 per month for access to their "indispensable" technology? Companies and professionals who have built their entire workflows around these tools will have no choice but to pay, becoming economic vassals to a handful of Silicon Valley firms.
The path forward requires strategic thinking about where real value lies in this ecosystem. Rather than chasing the latest AI wrapper or becoming dependent on proprietary models, we should focus on building capabilities in the infrastructure layers that will remain valuable regardless of which specific AI company rises or falls. This means investing in understanding the underlying technologies, developing expertise in areas like distributed computing, data infrastructure, open-source alternatives to proprietary AI systems, and even hardware.
I'll share more about "controlling the AI stack" during my talk at Habib Tech Summit in NYC on Aug 30. Get your tickets here.
Conclusion
LLMs, like ChatGPT, are one of many types of AI models that learn from data. Like all other AI models, they do not think, reason, or possess intelligence in the traditional sense. They can accomplish some remarkable tasks, but usually at an extremely high cost in terms of data requirements, environmental impact, and negative societal consequences.
AGI was never a major research goal for AI researchers and has only emerged recently as part of the Big AI hype cycle, and in part to distract us from problems that really matter, such as homelessness, genocide in Palestine, and growing inequities. We are not at risk of being overtaken by AI-powered machines. For Allah has literally breathed His Ruh into us to give us consciousness and awareness. That is not something that can be created by anyone other than Allah.
The real question isn't whether AI will replace human intelligence, it's how we use our Spiritual Intelligence to navigate a world shaped by these powerful but limited tools. An "AI bubble" is inevitable and we will have to lean on our faith more than ever before to weather it.
What are your thoughts? Where do you see yourself and your community in this AI landscape? How can we as Muslims maintain our independence while benefiting from technological progress?
Reply to this email and let me know!
Peace and blessings,
James
1. If you enjoy these reminders, support my work by pre-ordering my upcoming book "Spiritual Intelligence: 10 Lost Secrets to Thrive in the Age of AI" and get exclusive access to a chapter before the general public
2. Join the Spiritual MBA group coaching program where I help you pivot your career without having to quit your job
3. Book a 1:1 session with me to plan your "spiritually intelligent" career, brand, or business